Die nachfolgend beschriebene Struktur und der Ablauf innerhalb
des Master-Prozesses ist auch
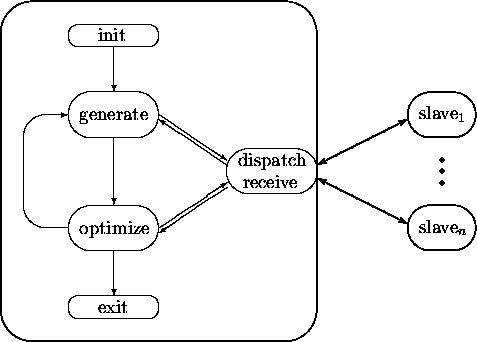
in Abb. 5.2 in Form eines Flußdiagramms dargestellt.
Anschließend wird der erste Baum aus drei Spezies generiert und die Kantenlängen vom Master-Prozeß selbst bestimmt (Punkt 4.). Hiermit ist die Initialisierung des Master-Prozesses abgeschlossen.
Nach Übergabe des letzten in diesem Schritt zu generierenden Baumes verharrt der Master-Prozeß in der Kommunikationsroutine und kehrt mit dem besten der berechneten Bäume wieder an diese Stelle zurück. Der gefundene Baum wird in der checkpoint-Datei abgelegt, und der Master-Prozeß geht dann zum Optimieren durch Rearrangement (optimize) über. Sollten noch nicht mehr als vier Spezies im Baum enthalten sein, beginnt der generate-Schritt mit dem besten Baum und der nächsten Spezies.
Auch jetzt verharrt der Master-Prozeß wieder nach Übergabe des letzten in diesem Schritt zu generierenden Baumes in der Kommunikationsroutine und kehrt mit dem besten der berechneten Bäume wieder an diese Stelle zurück. Wurde in diesem Durchlauf ein besserer Baum gefunden, wird dieser in der checkpoint-Datei abgelegt und der optimize-Schritt wiederholt, bis kein neuer optimaler Baum mehr gefunden wird.
Sind im Baum alle Spezies enthalten so geht der Master-Prozeß zum exit-Schritt über, anderenfalls wird mit dem diesem optimalen Baum und der nächsten Spezies wieder der generate-Schritt durchlaufen.
Sind keine Anfragen vorhanden, wird der übergebene Baum in eine Warteschlange eingereiht.
Anschließend an das Versenden wird geprüft, ob berechnete Bäume von Slave-Prozessen zurückgesandt wurden. Solche Bäume werden in eine mittels eines Heaps implementierte Priority-Queue (Cormen et al., 1990) eingereiht, um die besten gefundenen Bäume heraussortieren zu können.
Sind im generate-Schritt bzw. optimize-Schritt noch neue Bäume zu generieren, so kehrt der Master-Prozeß zu diesem Schritt zurück.
Sind im generate-Schritt bzw. optimize-Schritt keine neuen Bäume mehr zu generieren, so verbleibt der Master-Prozeß in dieser Routine, bis alle Bäume an die Slave-Prozesse verteilt und von diesen nach der Berechnung des ML-Wertes zurückgesandt wurden.
Anschließend wird der von allen berechneten Bäumen optimale Baum aus der Priority-Queue gezogen und der Master-Prozeß springt an das Ende des generate- bzw. optimize-Schrittes.
Anschließend wird den Slave-Prozessen übermittelt, daß die Analyse beendet ist. Der Master-Prozeß gibt dann den belegten Speicherplatz wieder frei und endet, nachdem auch die Slave-Prozesse gestoppt haben.
Während der Analyse wird kontinuierlich jeder auszuführende Schritt und dessen Laufzeiten in der Ausgabedatei dokumentiert.